浅谈Memcache
上图为Facebook登录页面图片
Facebook拥有庞大的社交网络和因此产生的频繁的请求,所以为了提高响应速度,使用了缓存的策略处理这一问题。通常情况下,用户的读写请求都会落到数据库上,而数据库的数据存储在磁盘上,磁盘低下的读写效率对响应的速度影响很大。所以,Facebook使用运行在内存中的Memcached作为中间件,先在其中查询相关数据,只有当Memcached中没有请求的数据时才向数据库查询。他们充分利用了内存远高于磁盘的读写速度,实现了业务的优化。下面,我会根据其论文谈谈他们具体是怎么做的。要特别指出的是,Memcache指的的整个系统,而Memcached则是服务器中的组件,众多Memcached服务器组成了Memcache系统,两者是不同的。
总体架构
Memcache的总体架构如下图所示
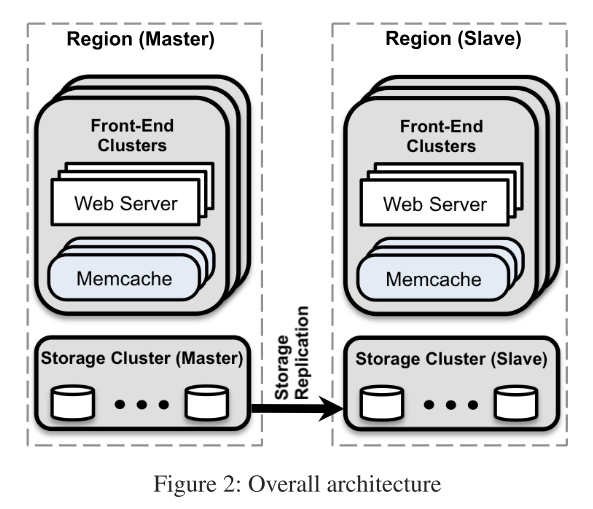
类似于Aurora和Spanner,Facebook也有Region的概念。现在,我们可以基本确定,Region指的是物理上实现地理分割的不同数据中心,这样划分可以根据用户的地理位置选择最近的数据中心来减少延迟。不同的Region之间只同步存储的数据。每个Region中有多个Cluster(集群),每个Cluster中又有多个Web服务器和Memcache系统,但每个Region只有唯一的存储集群。在这里,我想每个Cluster负责的业务应该是不同的,而每个Cluster中的多个服务器则应该是被用于实现均衡负载。
另外要讲的是Memcache的读写模型。Memcache使用的是Look-aside策略:服务器先尝试向Memcache读取数据,如果没有数据,则服务器再向数据库读取数据,读取完毕后将Memcache中的数据更新。示意图如下:
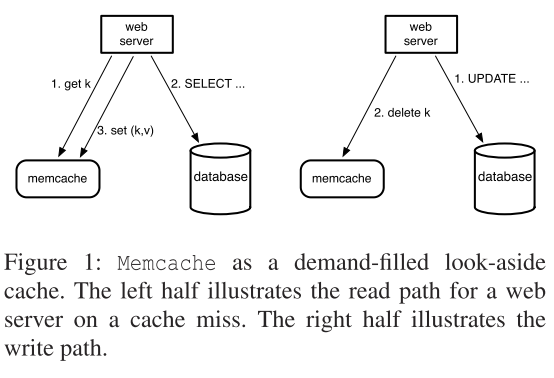
与之对应的是Inline策略,服务器尝试向Cache读取数据失败后,由Cache而不是服务器去数据库读取数据,再从Cache返回数据给服务器。
两者的区别在于处理数据缺失时的压力是由服务器还是缓存来承担。
下面,Memcache根据Cluster和Region分别讨论起内部的要求和优化。特别要说的是,在Facebook的应用场景中,读请求远比写请求多。
In Cluster
在Cluster中,Memcache主要关注两点,一是延迟(Latency),二是负载(Load)。
Latency
在Facebook的服务中,一次get请求不仅仅只读取单个K-V对,根据统计,一次页面的加载平均要从Memcache读取521个不同的数据,所以必须要采取一些措施来降低读取数据的延迟。
第一,Memcache使用DAG来表示数据直接的依赖关系。如果有两组完全不相关的数据,那么这两组数据就可以并行地读取,而单个DAG中的数据可以一次性提交读请求而不是每个数据提交一次。这里使用的并行和批读取数据有效地提升了读取速度。
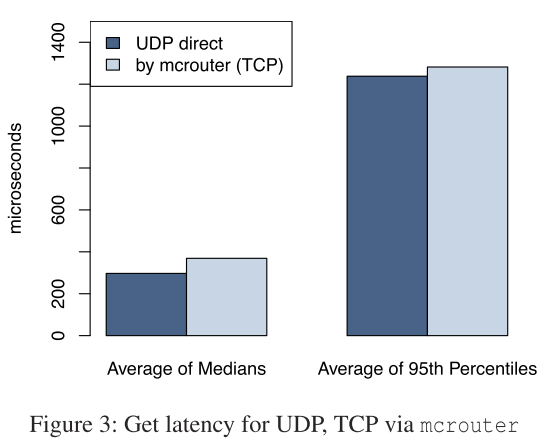
第二,Memcache使用UDP来发送读请求,TPC处理Set和Delete请求。由于UDP只负责发送而不考虑可靠性,也不维护链接,所以UDP要比TCP快。在大多数为读请求的情况下,使用UDP而不是TCP能减少读取的时间。而Set和Delete请求则要求必须可达,所以使用TCP。下图展示了UDP和TCP的性能比较。
第三,Memcache自己实现了一个类似TCP的拥塞窗口控制的机制以防止出现热点或阻塞。因为使用UDP传输读请求,所以自然也就没有TCP的拥塞窗口控制了。那么一旦出现大量的请求,UDP可能会使请求阻塞或者直接抛弃请求,抛弃请求则会使客户端重新发起请求,这两者都会影响整体的响应时间。所以Memcache在上层又实现了滑动窗口机制。
Load
在Look-aside模型中,当数据不再Memcache中时,会向数据库读取数据,在这种情况下,会出现很多情况,从而导致负载加重。Memcache使用下列方法减少负载。
第一,Memcache使用Lease处理两个问题:Stale Set和Thundering Herd。Stale Set指的是服务器在Memcache中设置了过期的数据,这个数据不能反映最新的值。Thundering Herd指的是某个值在一段时间内被大量地读和写,如果Memcache中存的数据不是最新的,读和写就要去请求数据库,这导致数据库的负载大幅增加。
为了解决Stale Set问题,在Cache 未命中的时候,Memcache会给客户端分配一个64位的Lease, 当拿到数据库数据之后,需要使用这个Lease来证明其身份。如果这个数据在返回之前被Delete或者更改了,也就是说,现在的数据是更新的,那么这个Lease就会被认为是无效的,从而拒绝旧的写入。
为了解决Thunder Herd问题,Memcache会每10秒钟给这大量请求中的一个请求分配Lease,其他的客户端则被要求等待。这个持有Lease的请求会继续其流程,访问数据库,更新Memcache中的数据。而当Memcache中的数据被更新后,其他客户端会重新发起请求,这时大多数就能拿到其想要的数据了。那么,在整个流程中,重复的查询和写入被减少为一次。论文中表示,Lease的引入将数据库的查询次数从17K/S降低到了1.3K/S。
第二,Memcache使用了Memcache Pool来分别处理不同场景的数据。论文中举了例子说,可以为经常访问但处理Cache未命中的开销不大的Key提供一个小的Pool 。可以为不经常访问的Key提供一个大型Pool ,因为对于这些Key来说,Cache未命中的代价很高。
另外,论文还讨论了应该使用分片还是复制降低负载。考虑系统总共每秒1M个请求,一次客户端发起的请求包含100个key。如果是使用分片的话,假设对应的数据平均分配在在两台机器上,100个Key的请求,每台机器存储的恰好是50个Key,那么两台每秒仍然要处理1M个请求,只是每个请求拿的key少了,这是存储问题,但是不能解决 QPS 过高。使用复制的话,那么每台机器就只需要处理0.5M个请求了。所以,Memcache最后使用复制实习均衡负载。
Handle Failure
在缓存系统中,我们仍然要考虑容错的问题。因为Memcache是缓存系统,所以不影响数据库本身的正确性,那么我们就无需考虑一致性的问题,只需要考虑均衡负载,把本应分配给崩溃机器的请求分配给其他机器。
Memcache将崩溃分为两种情况,很少一部分机器崩溃,很大一部分机器崩溃。
很少一部分机器崩溃的解决依赖自动修复系统,Memcache准备了约占总机器数1%的机器来接管崩溃机器的服务,这些备用机器被称为Gutter。一旦客户端发现请求没有回应,它们就认为该机器崩溃,然后将请求转发到Gutter服务区上。
很大一部分机器崩溃的话,Memcache会考虑将这个Cluster的请求转发到其他Cluster上,以保证服务能正常提供。
In Region
在这部分中,Memcache讨论了在同一Region中的一些问题。
Regional Invalidations
考虑一下,某个客户端的写入请求会使存储集群的数据发生变化,但是这里的变化没有经过其他Memcache或者其他客户端,所以Memcache中的缓存实际是过时的,但是其他客户端和其他Memcache都不能意识到这一点,所以必须由数据存储集群来处理这个问题。
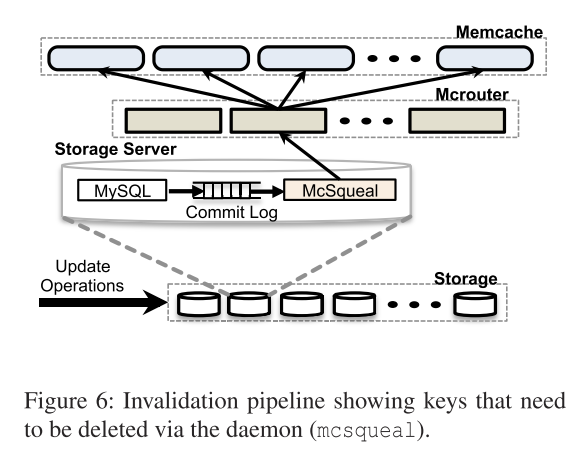
Memcache通过设置守护程序McSqueal来解决这个问题。当更新内容被Commit后,其会被送入到McSqueal中,McSqueal会判断这条语句是否会影响数据一致性。如果发现可能影响一致性的操作,它会将相关的信息送入Mcrouter中,再由Mcrouter发送给Memcache,这样Memcache就能根据相关的信息更新本地的数据,以此实现数据的一致性。在这里,McSqueal还使用批处理来降低系统的负载。其示意图如下。
Region Pool
由于每一个前端集群是独立处理发送过来的请求的,如果用户的请求被随机分配到每个集群,那么每个集群缓存的数据是差不多的。如果每个集群都保存一份相同的数据,那么有点得不偿失。所以Memcache设置一个Region Pool,即多个前端机器共享相同的Memcache集群。这样既能保证请求被响应,也能减少存储空间。
Warm Up
在一个新的Memcache集群上线时,整个集群是没有数据的,那么所有转发过来的请求都会未命中。这时候如果这些请求全部去查询数据库,那么数据库的压力会很大。所以冷集群要热身,它会先去其它正常运行的集群去做查询用户需要的数据,如果命中了就不用去数据库查了。这大大减少了数据库的压力。
Across Region
由于Facebook有多个Region,而且每个Region的存储集群都是独立的,所以要保证数据的一致性还要额外的操作。由于读请求不会影响数据一致性,这里考虑两种情况,一是主Region写,二是从Region写。
处理主Region写要简单一些,当主Region接受写请求后,它会将命令写入数据库,然后广播给其他Region。从Region接受到广播的信息后就利用我们之前提到的McSqueal来同步本地存储和Memcache之间的数据。
处理从Region写则要麻烦一点,因为从Region必须保证和主Region一致而不能单独处理请求,一旦从Region在本地执行请求而主Region不处理,就会出现数据不一致的情况。这里,Memcache牺牲了一点效率,它会把从Region收到的写请求打上标记然后转发给主Region。只有当主Region处理完该请求并发回到从Region时,才会清除这个标记,那么此时,数据也就一致了。
总结
Memcache最关键的一点在于它使用内存作为服务器和数据库之间的缓存,大大提高了数据访问的速度。在现在的系统设计中,Redis或者Memcache都是必不可少的一部分。另外,它在优化延迟和负载时使用的解决方案也相当有趣,虽然看起来很简单,但从数据上来看相当使用。但是,从我个人角度来看,他在实现缓存一致性的问题上解决方案不是很高效。想要在Memcache中实现跨Region之间或者跨Cluster之间的缓存数据一致性,那么必须要经过数据库,还要使用McSqueal和Mcrouter调整,效率想必是很低下的。不知道这后来有没有更好的解决方案。
