浅谈Amazon Aurora
上图为极地极光
Amazon在2017年的SIGMOD上发表了《Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases》并在对Amazon Aurora进行了介绍,简要描述了他们由于对传统MySQL性能的不满,而设计了Aurora来代替,其性能有相当大的提升。从时间和公司我们就可以看出,这是比较新的工业界的解决方案,有很高的学习参考价值。
Aurora的总体架构
虽然论文中在结尾时才对其作出总结,但是在开头就点名其架构,再步步深入会更加合理。下面是Aurora的总体架构图。
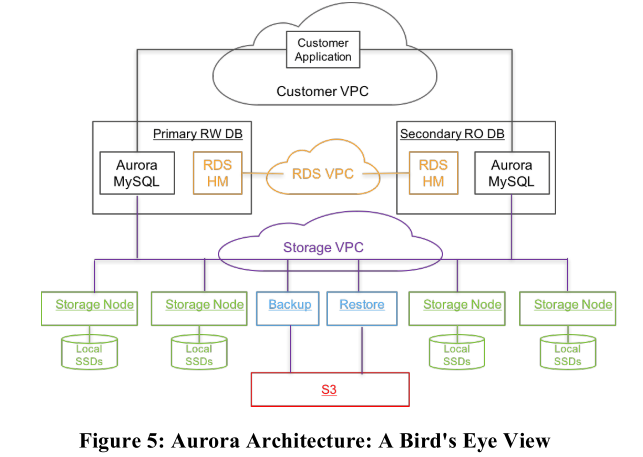
需要指出的是,由于Aurora是为了代替MySQL,而MySQL用于关系型数据库,所以Aurora仅负责处理关系型数据库的服务,即RDS(Relational Database Service)。我们其实可以从图中看出相当多的信息,Aurora仅有Primary RW(Read/Write) DB一个主节点用于处理写请求,而其余的则为从节点Secondary RO(Read-Only) DB用于处理读请求,论文中指出Secondary RO DB可以多达15个。另外,每个Aurora配备六个存储节点,其中有两个节点使用Amazon Simple Storage Service(S3)存储技术进行备份,而剩余4个节点则直接存储在本地的SSD上。
用户的应用通过Customer VPC接入,然后可以读写位于不同AZ(Availability Zone)的数据库。而不同的AZ分布于全球的不同的Region中。当用户的请求发送到Primary RW DB时,RDS HM(Host Manager)会检测到请求,并调用Aurora进行相应的操作。如果是写操作,则将相关信息发送给Secondary RO DB进行备份,同时将命令写入存储节点。如果是读操作,则直接从存储节点读取数据返回。
使用传统MySQL遇到的问题
Amazon在日常开发和维护中发现,计算能力和存储性能已经不再是其工作的瓶颈了,取而代之的是网络的流量。其实对于Amazon来说,只要有钱,CPU能用最好的就能解决计算能力的问题,机械硬盘不够用固态硬盘,固态硬盘不够就上内存,存储性能也解决了,但是网络的延迟靠大带宽是很难解决的,而拉近机房位置也是有上限的,必须要从业务逻辑和服务组件上找问题。所以他们发现了MySQL在分布式系统中消耗了大量的流量,还提高了延迟。具体如下图所示。
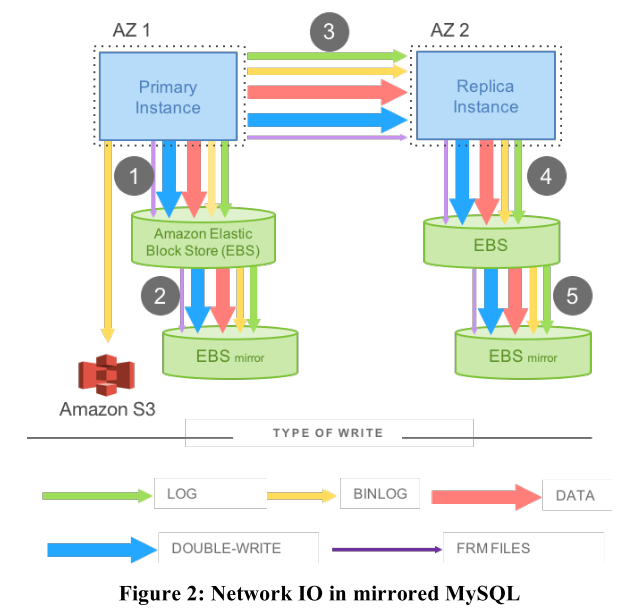
从图中我们可以看出,传统的MySQL如果想要执行一次写入操作必须经历以下几步:
- 主节点将数据写入EBS1
- EBS1将数据写入备份镜像EBS2
- 主节点将相关数据发送给从节点
- 从节点将数据写入EBS3
- EBS3将数据写入EBS4
其中,第1,3,5步是串行的,也就是说,只有第1步完成了,才能执行第3步,第3步完成了才能执行第5步。这无疑增加了服务器返回数据的延迟。另外传统的MySQL在写入和传输数据时还需要很多的额外信息,这又增加了网络带宽的消耗。也就是说,MySQL的使用在分布式系统产生了两个问题
- 应答延迟太高
- 消耗网络带宽太多
所以当Amazon发现使用传统MySQL的弊端之后,决定设计新的组件来代替MySQL以解决上述两个问题。
The Log Is The Database
上面我们提到,MySQL在同步数据的过程中发送的信息太多,这该怎么办呢?Amazon也算是家大业大,直接自己重新设计标准,以往的数据库是真的数据库,现在他们用WAL也就是Log来整合所有有用的信息并删去无用的信息,既减少了数据传输量又保证了需要保留的信息。同时,他们使用了链式复制结构代替主从结构,简化了保证数据一致性的复杂度。具体架构如下图所示。
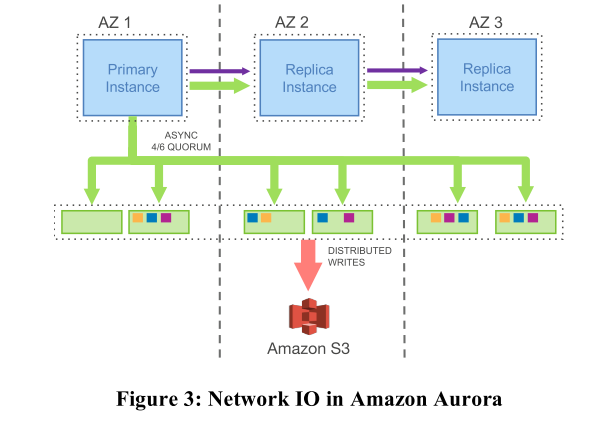
以三个副本为例,当位于AZ1的主节点收到写请求后,它将请求的相关数据直接写入六个存储节点中,然后,将数据和一些额外的信息通过链式复制结构传递给位于AZ2和AZ3其他节点。和上图进行对比,明显可以看到主从节点之间网络通信中传输的数据减少了,主节点向存储节点写入数据时也从五种数据变为一种。这里要特别指出的是,此处的数据已经从MySQ定义的Log变为Amazon为Aurora量身定制的Log。由于需要传输数据量的减少,同步所消耗的网络带宽也大幅地减少了。
另外,因为主节点负责将Log写入存储节点,而从节点仅存储Log不需要负责写入存储节点,这样就减少了在MySQL中额外的第四步和第五步操作的时间。而MySQL中的两级EBS存储操作也由一级Quorum的代替,就像上一篇文章提到的,两级存储的时间是两次操作的时间之和,而一级的Quorum操作的时间则是取决于Quorum中最长的应答时间。这样,Aurora也优化了应答延迟的时间。
在上一篇文章中我们提到,链式复制仅仅适用于节点较少且物理位置较近的情况。很巧的是,Amazon提供的服务中副本不会超过15个,而经典的情况仅有3个,而虽然不同AZ可能会跨节点,但是Amazon实在有钱,能让AZ之间的延迟低于2ms。在这种情况下,使用链式复制实在合适不过,还大大降低了保证共识的复杂度,简直是完美的设计。
Storage Node
上面,我们提到主节点将Redo Log写入存储节点。但是,此时Redo Log还未执行,需要在存储节点中执行相应的操作后才算真正完成。下面,我们再来看看Redo Log到达存储节点以后需要进行哪些操作。论文中给出的流程图如下。
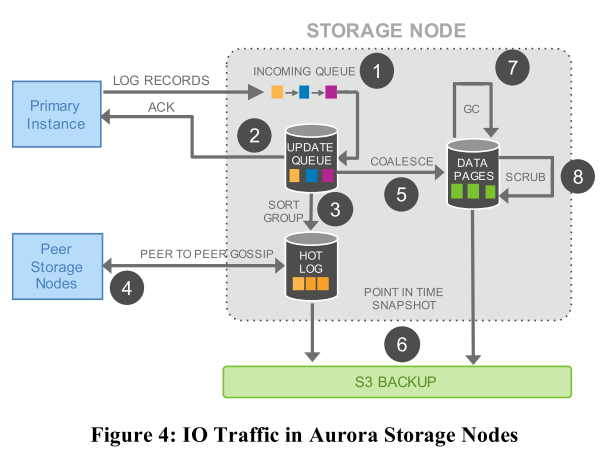
具体的流程解释如下
- 存储节点通过Incoming Queue接受主节点的Log。
- 存储节点将Log存到本地硬盘后向主节点发送ACK,用以确认Quorum。
- 由于网络的不可靠和Quorum机制,当前存储节点可能缺失了部分Log。在这一步,它将Log排序并找出缺失的Log。
- 通过和其他存储节点进行交换信息,将缺失的Log复制到本地,将所有Log填充完整。
- 到目前为止,系统中存储的仍是Log而非用户需要数据,这一步执行Log对应的操作,并写入数据库中。
- 定期地将数据存为快照并存入Amazon S3中。
- 定期地进行垃圾收集,删除过期数据。
- 用CRC定期检验数据。
从流程中我们可以看到,只有第一步和第二步可能影响应答延迟,其余的步骤都由存储节点在后台执行。这样一来,因为无需等待执行完毕,应答延迟就进一步降低了。
读写操作
Amazon在设计Log时,为了实现一些功能给它添加了一些标记,具体如下
- LSN:Log Sequence Number,相当于Log的自增主键,类似于Raft中的Index。
VCL:Volume Complete LSN,受到Quorum承认的最大LSN。
- CPLs:Consistenc yPoint LSNs,单个存储节点中已经收到ACK的最大LSN,所以每个节点各一个
- VDL:Volume Durable LSN,已经持久化最大的LSN,也就是CPLs中最大的LSN
- SCL:Segment Complete LSN,由每个段维护,代表段中已经持久化的最大LSN
在读写,复制和提交等操作中,Aurora会使用这些标记实现对应功能。
写操作
我们在之前的文章中提到,如果未执行的Log积压过多会产生很不好的后果。所以在写操作时,Aurora会设置VDL+N作为未分配LSN的上限,通过设置N的值来限制未写入磁盘的Log的条数。
读操作
为了提高效率,Aurora会在缓存中先查找是否有需要读取的数据,如果没有,再置换页面。在这里,Aurora要求置换页面中的LSN>VDL以确保数据为最新版本。这保证了所有页面的更新都已经持久化到日志并且在缓存区没有该数据页的情况下,可以根据 VDL 获取最新版本数据。
Fault-Tolerance
Aurora 将数据库文件切分成 10GB 大小的段(Segment)。在崩溃恢复的时候,Aurora要通过Quorum读得到VDL,并将大于此的Log阶段。由于在写操作时设置了LSN的上限,所以可以将需要Redo Log的LSN上限设置为VDL+N。然后重做已经标记的Log,就能恢复到初始状态,Aurora实验显示这个过程相当地快。
不一样的Quorum
我们上面提过,Aurora的六个存储节点部署在3个AZ中,每个AZ运行两个存储节点。Amazon考虑到可能整个AZ挂掉,导致两个存储节点崩溃,而AZ又有可能在同一个Region中,所以Aurora考虑的最坏情况是一个AZ崩溃加上一个存储节点崩溃,即AZ+1。
Aurora提出了以下两个要求:
- 在AZ+1崩溃的情况下不丢失数据,也就是保证读数据能力。
- 在AZ崩溃的情况下保证写数据能力。
于是Aurora提出了读写两种情况的Quorum。在写情况下,需要六个节点中的四张票,即4/6。在读情况下,仅需要六个节点中的三张票,即3/6.
很明显,写操作的Quorum和我们之前在Paxos和Raft中讨论的Quorum是一致的,也是2f+1需要f+1张票。而由于写操作每次至少写入四个节点,那么根据抽屉原理,每两次写操作至少有一个节点重复,那么读操作无论读哪一半都能在三个节点中读取到最新的全部数据。以此类推,哪怕一半的节点崩溃,Aurora也能读取到最新最全的数据。
但是,要特别指出的是,读Quorum的要求仅仅在恢复时才使用,正常读是不需要的。
从这里来看,其实这个Quorum也就是Raft中2f+1个节点容许f个崩溃的另一种说法。
总结
Amazon Aurora中描述的技术看起似乎很通用,使用WAL代替MySQL的信息,在存储节点执行命令而不是在本机执行,使用Chain Replication等等。但是能将这些技术恰到好处地使用在实际的系统中,并进行优化才是大厂的技术底蕴。比如Log的设计这一块,论文中就介绍地相当模糊,读写操作的细节也没有纰漏。这篇论文恐怕只算是对Aurora的惊鸿一瞥,真的想了解实现细节还得去Amazon内部看看。毕竟,Aurora在每个事务的IO花费的1/8,而事务处理量是MySQL的35倍,这可不是简单的系统设计就能完成的。
