浅谈Primary-Back Replication和Chain Replication
上图为Google提供的贪吃蛇游戏
前面两篇文章,我们讨论了分布式系统中为了维护一致性所使用的共识性算法Paxos和Raft。这些算法保证了各机器之间数据的一致性,但是Paxos算法针对的是平等的Replication策略,而Raft算法针对的是Primary-Back Replication策略。Replication策略和共识性算法的目的不同,它的设计是为了实现容错(Fault-Tolerance),即在一部分机器不可用后,仍能保证正常提供服务。下面,我将简要描述一下6.824中讨论的两种复制模型Primary-Back Replication和Chain Replication。
机器同步
为了能够实现集群能够及时接管服务,并提供相同的服务,集群需要保证不同机器之间的数据一致性。我们上面提到,要实现共识需要使用Paxos或者Raft算法,而我们需要对什么东西达成共识呢?这就要提到实现机器同步的两种方法,分别是State Transfer和Replicated state machine,其中差别如下
State Transfer:主机器将本身的状态变化全部传送给其他机器。
Replicated State Machine:由于业务的很多情况符合状态机的定义,所以只要保证所有机器初试状态相同,那么以相同的顺序执行相同指令后,它们的状态也是相同的。
举个例子,客户端发送{X=1,Y=X}的指令给集群。在State Transfer中,主机器执行这个操作后,将它发生变化的数据和值发送给其他机器,也就是{X=1,Y=1},然后其他机器将自身的数据修改为对应的值,以此实现各机器的数据一致性。而在Replication State Machine中,主机器发送{X=1,Y=X}的指令给其他机器,要求其他机器也执行这一操作,按照状态机的状态变化,也能实现数据一致性。
State Transfer的优点是不会消耗其他机器的计算能力,但是在实际情况下,发生变化的数据量比较大,它对集群的带宽和延迟要求都很搞。Replicated State Machine由于只发送指令,所以传输的数据量比较小,但是它要求各机器在本地执行指令,所以对机器的计算能力有一定要求。根据实际情况,一般集群中各机器的性能相当,所以计算能力不会成为瓶颈,而为了保证快速响应客户要求,必须尽量减少传输的延迟,State Transfer由于一次性传输的数据量大,所以在网络的传输延迟上很难实现要求。因此Replicated State Machine成为实际上的解决方案。
VM—FT
VMware在《The Design of a Practical System for Fault-Tolerant Virtual Machines》中介绍了基于虚拟机实现的Primary-Backup Replication的容错解决方案。其本质就是使用Replicated State Machine实现主从的数据一致性。
Deterministic Replay
在VM-FT中,它们将指令在副机器的执行称为Deterministic Replay。由于和数据库软件不同,有一些系统命令和时间息息相关,比如中断和时间戳,考虑到传输延迟,这就会使命令执行的结果不同,从而导致数据的不一致。所以这就给系统设计带来一些问题,论文将此分为三个目标
- 正确收集所有的非确定(Non-Deterministic)事件和操作,保证有在执行时有足够的信息在Replay时来修正操作
- 正确地在副机器上Replay非确定的事件和操作
- 保证以上两点不会降低机器性能
由于这个系统运行在VMware上,所以VMware可以收集所有它想要的信息并将其存储在文件中,能够正确地实现第一个目标。然后,主机器通过Logging Channel将需要执行的操作和相关的补充信息传递给副机器,因此可以保证第二个目标。在实际的测试中,VMware的实现也能够保证机器的性能,满足了第三点。
FT Protocol
由于主从机器通过Logging Channel进行通信,所以其中会产生一定的延迟而导致问题。假设主机器在收到请求后,在本地执行了该请求并将其传送给副机器,同时将结果反馈给客户端,但是副机器由于一些问题没有成功执行该指令,此时主从机器的数据是不一致的。如果主机器在此时崩溃,集群交由副机器负责,那么客户端再次查询数据就会得到不一样的结果。
因此,VMware提出了如下的要求:
输出规则:主机器只有在副机器已经接收并返回了该指令的ACK 后,才能回复客户端。其中,副机器必须成功执行了该指令后才能回复ACK。
其实就是要求主机器在副机器也执行完指令后,实现了整个系统的一致性,再回复客户端。其具体流程如下:
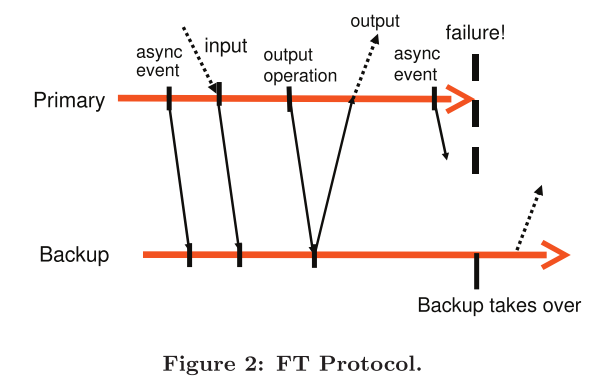
错误检测和恢复
为了检测错误,VM-FT使用了以下两种手段
- 使用定期发送UDP来实现各机器间的Heartbeating
- 由于整个系统基于VMware,所以可以通过检测Logging Channel的流量来查看是否正常工作
第一种方法和Raft中使用的类似,都是通过周期性地Heartbeats来检测是否活跃。第二种方法基于系统不断接受客户端请求的事实,只要客户发送了请求,为了实现主从同步,两者必须通过Logging Channel发送指令或者返回ACK,而如果相当长的时间内没有流量的话,就说明至少主机器可能已经崩溃。
一旦检测到主机器崩溃,那么副机器就会将Logging Channel中所有的指令执行完毕,以此到达主机器崩溃前的状态,然后在这个状态下回复客户端。而如果副机器崩溃了,主机器仅仅需要不再发送同步消息即可。
Logging Channel优化
为了保证主从的一致性,VM-FT还对Logging Channel进行了优化。如果副机器执行很慢,那么Logging Channel中的留存的信息过多,甚至填满了预留的空间,那么收到客户端请求时,主机器必须等待有空余空间才能发出请求,这使得客户端的体验很差。另一方面,如果主机器崩溃,副机器为了赶上主机器进度而需要花费的时间过多也会影响系统。所以VM-FT在通信中添加额外的信息,以此检测主从机器在执行同一指令上产生的延迟。如果这个延迟过大,VM-FT会减少分配给主机器的CPU算力,增加副机器的CPU算力,以此保证主从机器间的相对同步。
Brain-Split
假设两台机器都能正常工作,但是由于通信原因,他们不能通过Heartbeat来确认对方正常工作,那么主机器仍然保持主机器的角色,而副机器则会将自己晋升为主机器,此时系统中有两个主机器,产生了脑裂(Brain-Split)现象。很不幸,这种情况不能通过系统自身解决,因为他们不能正常沟通,而在VM-FT中也没有使用基于Quorum的选举机制,所以只能通过外部解决。
在VM-FT中,由于主从共享磁盘,所以可以通过磁盘这个中介来解决。可以在磁盘中记录当前是否有主机器,如果有机器想要成为主机器,那么它必须访问磁盘,读取这个字段,确认当前没有主机器,才能成为主机器。在论文中,这个过程被称为test-and-set 。而在分布式的系统中,则必须通过第三方服务器才能实现这一功能。
VM-FT总结
这篇论文发表于2010年,虽然距离现在有一段时间了,但是仍能看到后续设计的一些影子。比如Logging Channel中设计了Buffer来保存指令,这个设计其实就相当于WAL,它对Brain-Split的解决方案在今天仍然实用。不过,由于整体的实现是基于VMware,所以和实际的分布式系统仍然有一点差别。总而言之,我们对这篇论文最大的学习是对主从设计系统的简单了解。
遗憾的是,这篇文章没有讨论多个副机器的情况,也就是说,没有使用Paxos算法实现多个副机器的一致性。
CRAQ
《Object Storage on CRAQ High-throughput chain replication for read-mostly workloads》使用了一种类似于链表的复制模型Chain Replication。和Raft以及上面提到的主从模型不同,这个模型用很简单的方法就保证了数据的一致性。
Chain Replication
Chain Replication将每个结点连接成链表。其中写请求只能由头结点处理,读请求只能由尾节点负责。具体流程如下图:
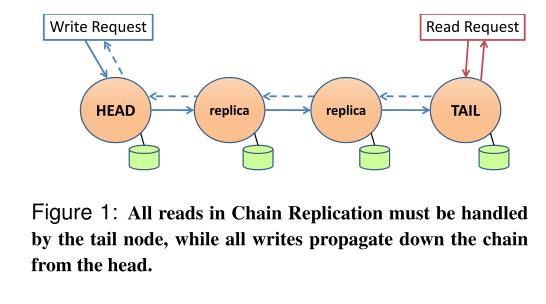
写请求:
- 头节点接受写请求,执行完毕后将其转发给后一个节点
- 所有节点都执行相关指令,同时将请求转发到下一个节点
- 等到尾节点也执行完相关指令后,会给上一个节点发送ACK
- 所有节点反向发送ACK,直到头节点
- 头节点收到ACK后,将结果返回给客户端
读请求:
读请求只能由尾节点处理,尾节点返回当前数据
我们可以看到,只有当所有节点都执行完相关操作后,写请求才能得到结果,能保证写的一致性。由于尾节点是最后更新数据的节点,所以尾节点中的数据就是当前系统最新的一致性数据,读请求总能得到已经达成一致的数据。这个模型很简单地实现了读写的数据一致性,但是问题是,所有的读操作都由尾节点来处理,相当于整个系统的读取压力都来到了尾节点,尾节点很可能崩溃。所以这篇论文提出了一些改进。
Chain Replication with Apportioned Queries(CRAQ)
这篇论文为了减少尾节点的压力,允许所有结点处理读请求,也就是名字中Apportioned Queries的含义。但是,由于读请求和写请求时并发的,有可能出现结点数据不一致时的读请求。所以这里还需要额外的处理。
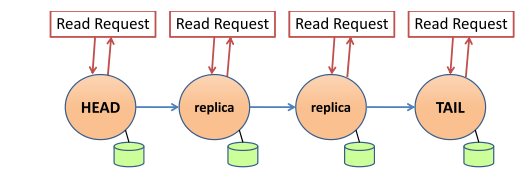
首先考虑最简单的情况,即整个系统数据保持一致的情况。这时,无论从哪个节点读取,数据都是正常的。示意图如下
其次,我们来考虑在处理写请求的同时,处理读请求的情况。其示意图如下
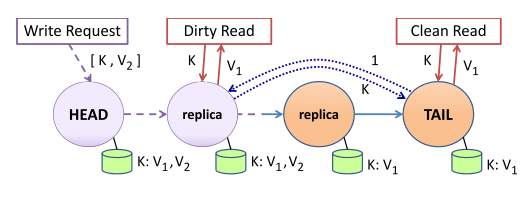
图中,头节点接受了写请求,并将其传送给第二个节点,第二个节点已经处理完毕。但此时,第三个节点和尾节点都还未进行相应的处理,导致前两个节点和后两个节点的数据不一致。CRAQ通过为数据添加版本并存储多个版本的数据来解决这一问题。
一次完整的写请求完成后,整个系统仍然能保证数据一致性,唯一不能保证的就是上图中写到一半的情况。其中,已经处理写请求的节点和尾节点数据不一致,而未处理写请求的节点则保持一致。所以,CRAQ要求处理完写请求的节点把自己标记为Dirty,而未处理的则无需标记。另一方面,尾节点始终存储能被整个系统承认的数据,即最新的保持了一致性的数据。所以,为了确定当前应该返回的数据,Dirty节点应该询问尾节点应当返回数据的版本。
这张图中的绿色圆柱表示数据库,我们可以看到,已经处理完写请求的两个节点的数据库中存有两个版本V1和V2的数据K,而后两个节点则只有V1版本的数据K。此时,第二个节点收到读请求,由于其数据库内有两个版本的数据K,而且本身标记为Dirty,所以它需要向尾节点发送询问请求。尾节点回复其应返回版本V1的数据K,此节点就按照尾节点的指示回复客户端V1版本的数据K。
综上所述,由于无论在CR还是CRAQ中,尾节点所存储的数据都是最新的具有一致性的数据,那么在可能出现的并发读写情况下,只需要向尾节点询问相关数据的版本,就可以确定应该回复的数据。
Membership Change 和 Failure Recovery
由于CRAQ中节点的结构类似于双向链表,所以Failure Recovery的策略其实就是Membership Change中的删除节点类似,也就是双向链表中节点的删除。设要删除的节点为D,某节点为N,其具体情况如下
如果D是N的后继:N需要把其所有数据传送给其新的后继。因为D有可能是上一节图中第二个节点的情况,那么写请求就不能传送给后继节点。如果D是尾节点,那么N需要D把所有ACK都反向传输完毕后再删除节点。
如果D是N的前驱:N需要把数据传送给其新的前驱。同时,如果D是头节点,N需要成为新的头结点。
节点的添加大同小异,只需要在新节点A是头结点和尾节点时进行特殊处理即可。
CRAQ总结
CRAQ对原有的Chain Replication进行了改进,平摊了读请求的压力,还用简单的模型保证了数据的强一致性。但是另一方面,从写请求的流程来看,需要线性地流经每一个节点势必增加系统的延迟。而Raft等算法则取决于单个机器的最长时间,如下图所示。
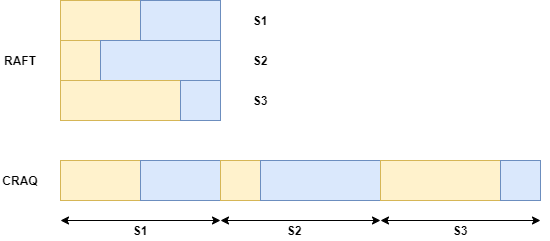
假设使用RAFT和CRAQ的系统中都有三个节点,黄色表示向非主节点写入指令需要的时间,蓝色表示该节点返回ACK花费的时间。可以看到,由于RAFT算法是并行的,它的实际时间取决于单个节点花费的最长时间。而CRAQ是串行的,它的时间是所有结点花费的时间总和。
如果想要使用CRAQ的模型进行备份,那么节点数量一定不能太多,最好节点不要跨机房,否则在网络传输上花费的时间就十分庞大了。
