浅谈Raft
上图为Steam同名游戏———RAFT
Raft算法是由Diego Ongaro和John Ousterhout于2014年提出的共识性算法。在斯坦福当助教时,他发现学生很难理解Paxos算法,所以他希望能用一种更简单易懂的算法来代替Paxos,以此为契机,他把便于理解作为目的,提出了Raft算法。
Paxos算法的不足
了解过Paxos算法的朋友都知道,Paxos算法最后提出了2PC的机制来保证共识。但是,我们也提到了,两段式的请求消耗过大,而且多Proposer的前提也很难实现,Proposal的数据结构也未提及。总之,Basic Paxos算法在工程上有非常多的实现困难。另一方面,也就是上文提到的,非常难于理解。而Raft正是为了解决这两大问题,它提出并总结了系统中节点的角色,各角色的功能和职责,需要使用的RPC及其参数和逻辑,甚至连数据结构都清楚地给出了定义。这简直就像手把手教开发人员实现算法。而也正是由于清晰详细的介绍,Raft算法理解起来也相当地容易,顺带一提,可能是为了“便于理解”,论文本身的行文和用词也相当地简单。
Raft
Raft算法使用Leader代替Paxos中的多个Proposer,使用Log Entry代替Proposal,以此简化问题。也因此,Raft算法将整个共识性问题划分为Leader Election,Log Replication两大块,同时,为了解决在崩溃时可能出现的问题,还提出了Safety的问题。此外,Raft还提供了Snapshot和Membership Change的解决方案。
Raft将系统中的角色划分为三种,Leader,Candidate和Follower。整个系统只有三种种通信方式,AppendEntryies PRC,RequestVote RPC和InstallSnapshot RPC。其中,AppendEntries RPC只能由Leader发出,用于向Follower追加Log Entry或者广播Heartbeats,RequestVote只能由Candidate发出,用于发起Leader Election,InstallSnapshot RPC只能由Leader发出,用于向Follower发送快照。
Leader Election
Raft将系统中的角色划分为三种,Leader,Candidate和Follower。所有机器初试为Follower,他们三者的转化关系如下:
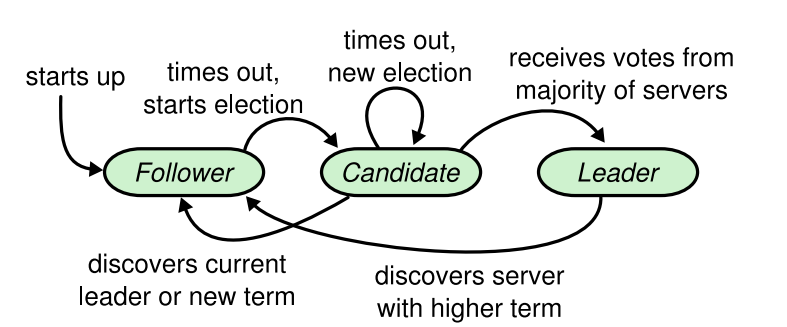
Follower->Candidate:当自身的计时器超时后,将自身转变为Candidate
Candidate->Leader:当Candidate获得Quorum的选票时,成为Leader
Candidate->Follower:当Candidate在RequestVote RPC中收到的Term大于该自己的Term,或者收到Term大于等于该自己Term的AppendEntries PRC时,就变为Follower
Leader->Follower:当在RPC中收到的Term大于该机器的Term时,自动变为Follower
要特别说明的是,只有Candidate才能成为Leader,所以只有Candidate才能发起Leader Election。下面,我们逐条来分析这么做的理由。
Follower->Candidate:首先,我们要声明的是,Raft规定了一个时限,如果在这个时限内没有收到Heartbeat(即不携带信息的AppendEnyties RPC),那么就认为超时了。假设在初始系统中,所有的机器角色都是Follower,但是只有Candidate才能发起选举,那么要怎么才能得到Leader呢?于是,这一条的作用就出现了。由于系统中没有Leader,那么就不会有Heartbeats,也就是说必定有一个Follower会超时,按着这一条的转换关系,此Follower会转变成Candidate,然后发出Leader Election请求,直到系统中出现Leader。还有一种情况,本来正常工作的系统的Leader崩溃了,同样地,由于收不到Heartbeats,其中的Follower会转变成Candidate发起Leader Election,保证系统正常运行。
Candidate->Leader:这一条其实无需多言,按照Paxos中提出的Quorum机制,获得多数承认的机器可以成为Leader。
Candidate->Follower:不同的Term代表不同的Leader周期,而且Term是自增的。Candidate会在发起Leader Election之前将自己的Term加一,代表自己比之前的Leader更新。而如果收到了一个大于自己的Term的RequestVote RPC,这就意味有机器在时间上比自己更新,所以就应该主动退出竞争。如果仅仅收到和自己Term相同的RequestVote RPC,这意味着在这一轮选举中有竞争者,谁能成为Leader就要看网络的连通情况,这就无需变为Follower了。而如果它收到了一个AppendEntries RPC且Term大于等于自己,而此RPC仅可能由Leader发出,这就意味本轮已经选出Leader或者有更新的Leader了,此时就应该退出竞争。
Leader->Follower:我们知道Term的大小代表Leader的新旧,也就是说,当在RPC中接收到的Term大于自己时,有一个新的Leader被选出了。这种情况有可能由于暂时的网络故障,使得此Leader不能与其他机器连通,而当剩余机器选出Leader后网络恢复了,那么此机器中存储的数据很可能不够完整,所以应该让位给新的Leader。
有了以上的要求,整个系统的角色转换已经可以顺利流转了。还需要关注的,是RequestVote RPC中的投票逻辑。在Raft算法中,使用“先来先投票”的原则,这个原则暗示了在多个Candidate竞争的过程中,与其他节点通信良好的会更有可能赢得选举。也就是说,选举出来的Leader与其他节点的通信延迟低,从而提升了系统的性能。但是,当本机器的Term大于RequestVote RPC中的Term时,说明本机器比发送请求的机器更新,此时应当拒绝请求。
不过,假如有一种极端情况:在某种条件下,所有的节点同时成为Candidate。而按照上述策略,它们首先会投自己一票,从而产生人均一票的情况,然后重新开始选举,如此往复。为了避免这种情况,Raft使用等待随机时间后再发起选举的解决方案。
Log Replication
Raft中的Log Entry对应于Paxos中的Proposal,但是它远比Propsal具体实际,也比Propsal强大。它是Write-ahead Log(WAL),也就是说,它在执行之前就被存储在可靠的磁盘上了,这种方案被广泛地用在实际的分布式系统中,以此提供一定的容错能力。
在Raft中,Log Entry使用Term和Index来标记自己,以此区别不同Log Entry并比较其新旧程度。其中,Term代表不同的Leader周期,而Index代表在同一个Leader周期中的不同Log Entry。Log Entry的整个生命周期如下:
- Client向Leader发送请求{x->1},Leader将其包装成Log Entry,追加到自己的Log Entries尾部,此时该log Entry的状态为Append
- Leader使用AppendEntries RPC将这条Log Entry广播给所有的Follower,要求Follower也将其追加到自己的Log Entries的尾部
- 当Follower完成后,会送回AppendEntries RPC的回答,这个回答可能是成功,也可能是失败。
- 如果Leader收到Quorum个的成功的回应,他会将其状态设为Commited,表示已经在Quorum个Follower中写入该请求。如果没有,则重新发送。
- 在将该Log Entry设为Commited后,Leader就可以在机器中执行{x->1},同时将结果返回给Client。此时,该Log Entry的状态为Applied。各Follower则会在后台选择时间执行该命令。
综上所述,Log Entry一共有三种状态,Append,Commited和Applied。
Append状态表示仅仅被追加到了Leader的Log Entries中,此时既未被其他机器承认,也未被执行。唯一的好消息是,它被存储在Leader的磁盘中了,哪怕Leader暂时崩溃了,只要系统恢复后该机器仍然是Leader,也能读取其中内容,继续向下执行操作。
Commited状态表示此Log Entry已经得到了系统中Quorum个机器的共识,在这个状态下,它能够承受2f+1个机器中f个机器的崩溃,一旦系统恢复,它可以被安全地执行。
Applied状态表示它已经被执行过了,只要处于该状态,那么在形成快照时,它就可以被删除。不过,由于各机器都在后台执行命令,Raft仅保证Log Entry最后能被执行但不保证执行的一致性。
在追加Log Entry和维护Log Entry的过程中,Raft必须维护一下两条准则
- 如果在两个不同机器上的Log Entry拥有同样的Term和Index,那么这个Log Entry包含的Command相同
- 如果在两个不同机器上的Log Entry拥有同样的Term和Index,那么在这个Log Entry以前所有Log Entry都相同
由于每个Term仅有一个Leader,而Leader给每个Log Entry标记的Index不同,这就意味着Log Entry的Term和Index构成了全局唯一性。这个特性保证了第一条准则。
第二个准则由AppendEntries RPC的内部逻辑保证。AppendEntries PRC的请求中带有PrevLogIndex和PrevLogTerm两个参数用来验证Follower中最新的Log Entry是否和Leader一致,这两个参数是AppendEntries RPC中Log Entry的前一个Log Entry的Index和Term。一旦发现不一致,Follower被要求删掉此Log Entry并返回失败,在一下次AppendEntries RPC时,Leader会将这两个参数改为当前Log Entry的前两个Log Entry的Index和Term,以此类推。直到找到Follower和Leader匹配的位置后,Leader会把从匹配位置开始直到最后的Log Entry全部发送给Follower。Leader通过这种强制更换的方式实现了第二条准则。这里要特别指出的是,在正常情况下不会出现Follower和Leader不匹配的情况,只有在机器崩溃的时候才可能出现,而这种强制更换掉的Log Entry中有两种情况,被删除和位置变更。其中被删除的Log Entry只有可能处于Append状态,位置变更的Log Entry则处于Commited状态。
除此之外,AppendEntries RPC还要喝RequestVote RPC一样检查当前Term是否小于请求中的Term,否则将拒绝请求。在Leader的CommitedIndex大于本机器的CommitedIndex时,还应将本机器的CommitedIndex设为LeaderCommitedIndex和本机最新Index中的小的值,从而能跟上Leader的处理节奏。
Safety
由于系统中的机器有可能发生故障和崩溃,而此时会产生许多意外的情况,所以Raft给Leader Election和Log Replication增加了一些限制来解决这些情况。
Election Resitriction
如果按照原来的Leader Election的要求,那么我们可能会出现下面的情况。有一台原来网络状况不是那么好的机器,它能赶得上当前的Term,但是不能收到最新的Log Entry,假设它在同Term中总比其他机器少一个Log Entry。此时由于某种原因,它的网络状况改善了并按照选举原则拿到多数票,赢得了选举,成为Leader。那么,按照AppendEntries RPC的要求,它会删除掉其他机器中比它快的那一个Log Entry,然而这个Log Entry已经被Commited了,这就出现了问题,这个系统虽然保证了一致性但是却损失了信息。所以Raft在RequestVote RPC中添加了一个逻辑:通过和AppendEntries RPC一样的方式进行比较,如果Candidate的Log Entry比自己的旧,就投拒绝票,只有Candidate和自己一样新或者比自己更新才投同意票。
基于这个约束和AppendEntries RPC中的Quorum原则,如果2f+1个中有f个机器未收到最新的Log Entry,那么在选举中,他们最多只能拿到f票,从而无法成为Leader。我们可以得出结论,只有拥有最新的Log Entry的Candidate才能成为Leader。
Committing Entries From Previous Terms
假设有如图情况
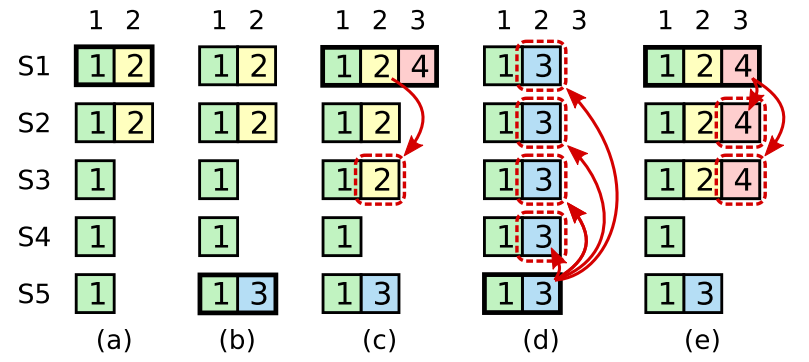
其中,黑框代表Leader,Log Entry中的数字代表Term。由图可知,在Term(2)中,S1是Leader,它向S1和S2写入了Log Entry但是由于某些原因宕机了。此时,S5得到S3,S4和自己的投票成为Term(3)的Leader。但是,仅仅把Log Entry追加到本机上后,在向其他服务器发送Log Entry之前就崩溃了,注意,此时该Log Entry未被Commited。此时,S1又成为了Term(4)的Leader,在它把一个Log Entry复制给S3后,由于某些原因又崩溃了。按照上述的选举原则,S5仍然可以拿到S2,S3,S4的投票,当他成为Term(5)的Leader后,它还未收到任何Client的请求,于是它按照AppendEntries的的逻辑使用强制替换保证了一致性。但是,值得注意的是,它使用Term(3)的Log Entry覆盖了Term(4)的Log Entry。这种情况是不被允许的,旧的数据是不能覆盖新的数据的。于是,Raft提出了约束:只有和当前Term相同的Log Entry才能被Commited。
通过这个约束,上述的蓝色Log Entry就不会在重启后重新发送给其他机器,而客户端也永远不会收到它想要的答复。此时,如果Client需要此命令被执行,那么它需要重新发送请求。
Membership Change
上面的三个部分其实已经完成了Raft算法的主体介绍,这一部分讨论的是Raft算法如何解决成员变更的问题,成员的组成在Raft中被称为Configuration。成员变更意味着Quorum的总人数和成员的变化,所以无论是对Leader Election还是Log Replication都有很大的影响。
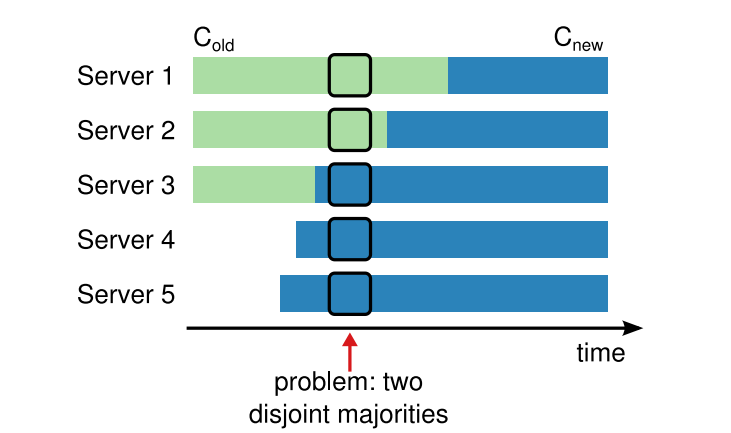
如上图所示,在指定时刻,S1,S2在旧的Configuration中,S3,S4,S5在新的成员中,但此时整个的成员交接还未完成。所以,对于旧的Configuration来说,S1和S2组成了Quorum,对于新的Configuration来说S3,S4,S5组成了Quorum。那么此时就出现了两个Quorum,可以实现两种决策,这是Raft算法必须要避免的。
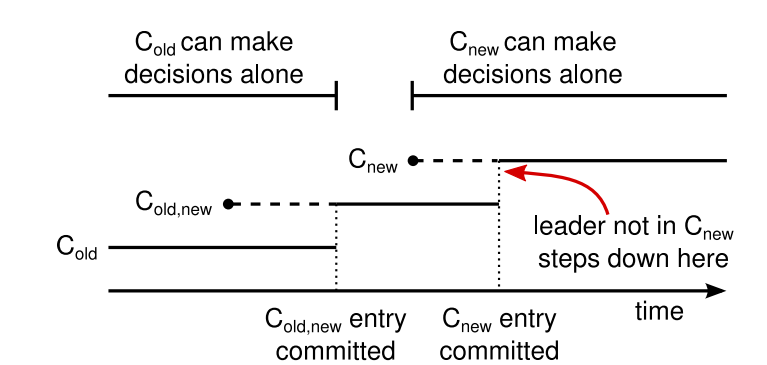
Raft算法使用Log Entry实现成员变更。当需要进行成员变更时,Leader将包含新Configuration的Quorum以及旧Configuration的Quorum的Log Entry发送给Follower,等待Quorum的回复以此将其设为Commited。在此过程中,由于有部分成员已经收到此Configuration,所以所有的决策都需要在此条件下进行,而由于Leader包含这个Configuration,所以能确保这一点。由于中间态的Configuration既包含旧的Quorum又包含新的Quorum,所以所有的决策都需要两方的同意,这就保证的在这个阶段的决策能符合新旧Configuration的要求。然后,新的Configuration才被广播给所有Follower。同样地,由于至少有一个成员在新的Configuration下工作,所以一旦被广播给Follower,所有决策都要在新的Configuration下进行。这样,就完成了成员变更。
总得来说,Raft引入了一个中间态,在这个中间态中,既包含旧Configuration的Quorum,又包含新Configuration的Quorum,以此满足在此期间决策的正确性。
Snapchat
在Log Replication中我们说,所有Commited的Log Entry都要被记录在磁盘上,但是磁盘的容量是有限的,如果达到上限了怎么办?很明显地,Raft使用Snapshot记录下机器中此时的状态,再将最新执行的的Log Entry以前的Log Entry全部删除就可以了。
详细地说,Raft算法允许每台机器各自执行Snapshot,而Snapshot必须记录它最后包含的Log Entry的Term和Index作为LastIncludedEntry和LastIncludedIndex来标记自己记录的位置。然后将这个Log Entry及其之前的全部删除就能达到清理空间的效果。
但是,有一个情况我们必须考虑。假如一台机器网络情况和运行状况都很差,它最新的Log Entry甚至没有其他机器的快照新,这时候使用AppendEntries RPC是不能帮助它的,因为对应的Log Entry已经被删掉了。这里就需要Leader使用新的RPC,InstallSnapshot RPC来帮助它。InstallSnapshot RPC包含Leader的Snapshot的数据,LastIncludedEntry和LastIncludedIndex等信息,当这个Follower使用Snapshot更新自己的状态后,它就需要使用LastIncludedEntry和LastIncludedIndex来更新自己记录的信息,然后Leader可以再使用AppendEntryies RPC去更新它的Log Entry。
总结和思考
Raft相对于Basic Paxos做了很大的改进。
首先,它使用Leader代替了多Proposer,跳过了Prepare阶段,减少了网络请求的消耗。
其次,它显式地明确了使用WSL来作为Propsal的载体,不仅降低了开发难度,还提供了相当的容错能力。
最后,它对容错的场景进行了深入地考虑并且给出了相应的解决方案。
最重要的,Raft在保证共识性的同时明确地实现了数据的一致性,这对于算法落地来说实在难能可贵。
但是,Raft使用的成员变更看起来并不是一个很好的方案。我认为在实践中使用Zookeeper作为成员变更的中间工具可能更加合适易行。
总得来说,Raft算法实至名归,对得起Practical和Understandable的主旨。在GitHub上,有相当部分的项目都使用Raft算法作为他们的核心算法。
